Evaluating the Jouve Cerebrals Crystallized Educational Scale (JCCES): Reliability, Internal Consistency, and Alternative Answer Recognition
This study aimed to evaluate the Jouve Cerebrals Crystallized Educational Scale (JCCES), an assessment tool designed to measure crystallized cognitive skills. A comprehensive analysis was conducted on the answers provided by 1,079 examinees, with a focus on reliability and internal consistency. Classical Test Theory (CTT) and Item Response Theory (IRT) methods, such as kernel estimator and Bayes modal estimator, were employed to analyze the data. The study found excellent internal consistency for the JCCES, with a Cronbach's Alpha of .96. The items demonstrated a wide range of difficulty levels, standard deviations, and polyserial correlation values, suggesting that the test covers a broad spectrum of cognitive abilities and content areas. The kernel estimator method allowed for a more accurate evaluation of examinees' abilities and highlighted the importance of considering alternative answers in test design. The two-parameter logistic model (2PLM) provided a good fit for the majority of the items. These findings contribute to the validation and refinement of the JCCES and support its use as a comprehensive assessment tool for crystallized cognitive skills.
JCCES, Classical Test Theory, Item Response Theory, kernel estimator, Bayes modal estimator, two-parameter logistic model, internal consistency, reliability
Psychometric theories and tools have played a critical role in the assessment and evaluation of cognitive abilities in various domains, including intelligence and educational achievement (Anastasi & Urbina, 1997; Messick, 1989). One such tool is the Jouve Cerebrals Crystallized Educational Scale (JCCES), which is designed to measure crystallized intelligence and, to a lesser extent, educational achievement (Jouve, 2023). The JCCES is based on the Cerebrals Cognitive Ability Tests (CCAT), developed in 2004 by a working group of psychologists and non-psychologists from the Cerebrals Society. The test has undergone several revisions and is now composed of 129 items distributed across three subtests: Verbal Analogies (VA), Mathematical Problems (MP), and General Knowledge (GK).
To ensure the reliability and validity of the JCCES, the developers employed various psychometric methodologies, such as Classical Test Theory (CTT; Allen & Yen, 2002; Lord & Novick, 1968) and Item Response Theory (IRT; van der Linden & Hambleton, 1997). These methods have been widely used in the development of psychometric tests, providing robust estimates of item appropriateness and test reliability. The JCCES has demonstrated excellent internal consistency, with a Cronbach's Alpha of .96, which is comparable to well-established cognitive ability tests such as the Wechsler scales (Wechsler, 1997, 2008).
This study aims to provide a detailed analysis of the psychometric properties of the JCCES, focusing on its internal consistency and item-level characteristics. Through a comprehensive literature review, the study establishes the context and relevance of psychometric theories and their application in the development of the JCCES. The selection of specific methodologies, such as CTT and IRT, is justified based on their suitability for the evaluation of the test's properties (Embretson, 1996).
The JCCES's development process has been informed by the works of prominent scholars in the field of psychometrics, including Nunnally and Bernstein (1994), who have suggested that a minimum alpha coefficient of .80 is desirable for a set of items to be considered reliable. Additionally, the use of IRT methods (van der Linden & Hambleton, 1997), such as kernel estimation and Bayes modal estimation, has allowed for a more nuanced analysis of the test's items, particularly in the context of verbal analogies where the focus is on reasoning rather than vocabulary and lexical knowledge.
The JCCES represents a valuable contribution to the field of psychometrics, demonstrating strong internal consistency and robust item-level characteristics. This study provides a comprehensive analysis of the test's properties, drawing upon a wealth of psychometric theory and empirical research (e.g., Allen & Yen, 2002; Anastasi & Urbina, 1997; Lord & Novick, 1968; Messick, 1989) to establish its context and relevance within the broader field of intelligence and educational assessment. By providing this in-depth examination, the study aims to enhance the understanding of scholars in the field of psychometrics and facilitate the interpretation of the JCCES's results in various applications.
Literature Review
This literature review will delve into the concepts of internal consistency, crystallized intelligence and educational achievement, Classical Test Theory (CTT), and Item Response Theory (IRT). It will also focus on the reliability and validity of tests of crystallized intelligence, compare the use of CTT and IRT for assessing reliability, and, although not all of these techniques are used in the present study, the literature section will discuss different methods used to assess internal consistency, such as Cronbach's alpha and item-total correlations.
Internal Consistency.
Internal consistency is a critical element in establishing the reliability of psychological and educational tests, as it helps to ensure that the items within a test are indeed measuring the same underlying construct (Allen & Yen, 2002). This section will delve deeper into the different methods for assessing internal consistency, including Cronbach's alpha, item-total correlations, and split-half reliability.
Cronbach's alpha (Cronbach, 1951) is the most widely used method for assessing internal consistency. It is a coefficient that ranges from 0 to 1, with higher values indicating greater internal consistency. Cronbach's alpha is based on the average inter-item correlation, which is the mean of all possible item pairs' correlations within a test. It is important to note that the value of Cronbach's alpha can be influenced by the number of items in a test and the inter-item correlations (Tavakol & Dennick, 2011). While a commonly accepted minimal threshold for satisfactory internal consistency is an alpha of 0.70 or higher (Nunnally, 1978), or even of above .80 in magnitude (Nunnally & Bernstein, 1994), some researchers argue that the acceptable value may depend on the context and purpose of the assessment (Streiner, 2003).
Item-total correlations provide another means of assessing internal consistency by examining the relationship between individual item scores and the total test score, excluding the item in question (Nunnally, 1978). A high item-total correlation suggests that the item is consistent with the overall test and contributes to the measurement of the underlying construct. Items with low item-total correlations may indicate that they are not well-aligned with the construct being measured and could potentially be revised or removed to improve the test's internal consistency (Clark & Watson, 1995).
Split-half reliability is a method that involves dividing a test into two equivalent halves and calculating the correlation between the two sets of scores (Spearman, 1910). This approach provides an estimate of internal consistency by determining the extent to which the two halves of the test yield similar results. The Spearman-Brown prophecy formula (Brown, 1910; Spearman, 1910) is often used to adjust the split-half correlation to reflect the reliability of the full test. Although split-half reliability offers a useful estimate of internal consistency, it is sensitive to the specific method used to divide the test into halves and may produce varying results depending on the chosen partition (Eisinga, et al., 2013).
Each of the methods discussed above has its own strengths and limitations (Anastasi & Urbina, 1997), and researchers often use multiple approaches to evaluate internal consistency. For instance, Cronbach's alpha provides a single value that is easy to interpret and compare across tests, but it can be sensitive to the number of items and the range of inter-item correlations. Item-total correlations offer detailed information at the item level but do not provide an overall test-level index of internal consistency. Finally, split-half reliability estimates are less sensitive to individual item characteristics, but they can be influenced by the specific method of dividing the test. By using a combination of these methods, researchers can develop a more comprehensive understanding of a test's internal consistency and make informed decisions about potential improvements to the test's design and content.
Crystallized Intelligence and Educational Achievement.
Crystallized intelligence has been consistently linked to educational achievement. As crystallized intelligence encompasses an individual's acquired knowledge and skills, it is not surprising that it plays a significant role in academic performance. In this section, we will review research investigating the relationship between crystallized intelligence and educational achievement.
Early research on the relationship between crystallized intelligence and educational achievement demonstrated a strong association between the two constructs. For instance, Gustafsson (1984) found that crystallized intelligence was a strong predictor of academic performance in various subjects, such as reading, mathematics, and science.
Subsequent research has continued to provide support for the relationship between crystallized intelligence and educational achievement. Deary, Strand, Smith, and Fernandes (2007) conducted a longitudinal study investigating the link between crystallized intelligence and educational attainment. Their results indicated that crystallized intelligence, as measured by vocabulary and general knowledge tests, was a significant predictor of educational achievement in subjects such as English and mathematics.
Research has also identified factors that can moderate the relationship between crystallized intelligence and educational achievement. For example, socioeconomic status (SES) has been found to influence the strength of the association between crystallized intelligence and academic performance (Sirin, 2005). In low-SES contexts, the relationship between crystallized intelligence and educational achievement tends to be weaker, potentially due to the lack of access to resources that facilitate the development of crystallized intelligence.
The strong link between crystallized intelligence and educational achievement has important implications for educational practice. Schools and educators can use crystallized intelligence assessments to identify students who may need additional support, as well as to inform the development of targeted interventions aimed at improving academic performance. Furthermore, efforts to enhance crystallized intelligence through explicit instruction in vocabulary, general knowledge, and other related skills may lead to improvements in overall educational achievement.
There is a wealth of research supporting the relationship between crystallized intelligence and educational achievement. This association has been consistently demonstrated across various age groups and subject areas, highlighting the importance of crystallized intelligence in academic performance. Given the strong link between the two constructs, educational practices aimed at enhancing crystallized intelligence may be an effective way to improve educational outcomes for students.
Classical Test Theory (CTT).
Classical Test Theory (CTT) has long been the dominant psychometric framework for analyzing test data, providing researchers and practitioners with valuable insights into test reliability and validity. The following section delve deeper into the application of CTT in the context of crystallized intelligence tests, highlighting key studies and advancements in this area.
CTT is grounded in several key concepts, including the true score, error, and observed score. The true score represents an individual's "actual" ability on a construct being measured, while the error represents the random fluctuations that may occur in test scores due to various factors (e.g., testing conditions, fatigue). The observed score is the sum of the true score and error. In CTT, the goal is to minimize the error component, thereby increasing the reliability of the test scores (Novick, 1966).
In CTT, reliability is defined as the proportion of true score variance to the total variance of the test scores (Lord & Novick, 1968). There are several methods to estimate reliability within the CTT framework, including test-retest reliability, parallel forms reliability, and internal consistency reliability. The latter is commonly assessed using Cronbach's alpha (Cronbach, 1951), which is a measure of the average inter-item correlation among test items.
CTT has been applied to assess the reliability of various tests of crystallized intelligence, such as the Wechsler Adult Intelligence Scale (WAIS; Wechsler, 1955) and the Woodcock-Johnson Tests of Cognitive Abilities (Woodcock & Johnson, 1989). For instance, the WAIS is a widely used measure of intelligence that comprises subtests designed to assess different aspects of crystallized intelligence, such as vocabulary, comprehension, and general knowledge. Researchers have utilized CTT to estimate the internal consistency of these subtests, typically reporting high reliability coefficients.
While CTT has been instrumental in assessing the reliability of crystallized intelligence tests, it is not without limitations. Some critiques include the assumption of unidimensionality, the dependence of reliability estimates on the specific sample used, and the inability to account for individual differences in item functioning (Hambleton & Jones, 1993). These limitations have led to the development and adoption of alternative psychometric frameworks, such as Item Response Theory (IRT), which can address some of these concerns and provide a more nuanced understanding of test reliability and individual differences in performance on crystallized intelligence tests.
Item Response Theory (IRT).
Item Response Theory (IRT) is a family of statistical models that describe the relationship between a person's latent trait (e.g., ability) and the probability of responding correctly to individual test items (Birnbaum, 1968). IRT models are based on the idea that the probability of a correct response is a function of both the individual's ability and the item's characteristics, such as difficulty and discrimination (Hambleton & Swaminathan, 1985). In contrast to CTT, which focuses on test scores as a whole, IRT provides detailed information about the functioning of individual items and allows for more accurate comparisons between individuals with different ability levels.
There are several different IRT models, which can be broadly categorized into unidimensional and multidimensional models. Unidimensional models assume that a single latent trait underlies the responses to all items, while multidimensional models allow for multiple latent traits (Reckase, 2009). Some common unidimensional IRT models include the one-parameter logistic model (1PL; Rasch, 1960), the two-parameter logistic model (2PL; Birnbaum, 1968), and the three-parameter logistic model (3PL; Lord, 1980). Each model has its own set of assumptions and is suitable for different types of data and test situations.
IRT offers several advantages over CTT, including:
IRT has been used to assess the reliability and validity of various measures of crystallized intelligence. One example is the Woodcock-Johnson Tests of Cognitive Abilities (WJ; Woodcock & Johnson, 1989), which employs IRT to estimate item parameters and individual abilities in the domains of verbal ability, reasoning, and knowledge. Another example is the Wechsler Adult Intelligence Scale (WAIS-IV; Wechsler, 2008), which uses IRT-based methods to develop and analyze items that assess crystallized intelligence, such as vocabulary and general knowledge. These applications demonstrate the utility of IRT in evaluating and refining measures of crystallized intelligence, as well as the potential for more accurate and nuanced assessment of individual differences in this domain.
Comparing CTT and IRT for Assessing Reliability.
Several studies have compared the performance of CTT and IRT in assessing the reliability of tests of crystallized intelligence. In general, IRT has been shown to have certain advantages over CTT, including:
Although IRT has several advantages over CTT, some studies have found that the two methods perform similarly in certain situations. For example, Embretson & Reise (2009) found that CTT and IRT produced comparable reliability estimates for tests with a small number of items and relatively low discriminative power. This finding suggests that, in some cases, CTT may still provide useful information about the reliability of a test, particularly when the assumptions of IRT are not met or when the test has a limited number of items.
When comparing CTT and IRT for assessing the reliability of tests of crystallized intelligence, researchers need to consider the underlying assumptions of each method, as well as the specific context in which the test is being used. In general, IRT is preferred when the test includes items with varying difficulty levels and discriminative power, as it provides more accurate and informative reliability estimates. However, CTT may still be appropriate in situations where the test has a small number of items, or when the assumptions of IRT are not met.
Assessing Internal Consistency in CTT and IRT.
Cronbach's alpha is a widely used measure of internal consistency within the framework of CTT. It is based on the average of all possible split-half reliability coefficients (Cronbach, 1951). The value of Cronbach's alpha ranges from 0 to 1, with higher values indicating greater internal consistency. In CTT, internal consistency is assumed to be constant across all individuals taking the test, regardless of their ability levels (Nunnally & Bernstein, 1994).
Despite its popularity in CTT, Cronbach's alpha has been criticized for its use in IRT. One major issue is that Cronbach's alpha assumes a linear relationship between the items and the latent trait being measured (Sijtsma, 2009). However, IRT models are inherently nonlinear, as they account for the varying difficulties of items and differences in individual ability levels (Baker, 2001). Consequently, using Cronbach's alpha in IRT may lead to biased estimates of internal consistency.
To address the limitations of Cronbach's alpha in IRT, Bock and Aitkin (1988) proposed the marginal reliability index. This index is derived from the IRT model and accounts for both the item parameters and individual ability estimates. It provides a more appropriate estimate of internal consistency for IRT-based tests, as it takes into consideration the nonlinear relationship between items and the latent trait (Bock & Aitkin, 1988).
Another alternative to Cronbach's alpha in IRT is the test information function (TIF; Lord, 1980). The TIF is a measure of the precision of a test at different points along the ability continuum. It is based on the sum of the item information functions, which describe the amount of information each item provides about an individual's ability level. High TIF values indicate greater internal consistency and measurement precision at specific points on the ability continuum (Lord, 1980).
When comparing internal consistency estimates between CTT and IRT, it is essential to consider the differences in the underlying assumptions and models. While Cronbach's alpha may be appropriate for CTT-based tests, it may not provide accurate estimates of internal consistency in IRT-based tests. Instead, using indices such as the marginal reliability index or the TIF can provide more accurate and nuanced estimates of internal consistency within the IRT framework. These methods also allow for a better understanding of the reliability of a test across different ability levels, which is an important consideration in the evaluation of psychometric properties.
Studies Using Both CTT and IRT to Assess Internal Consistency.
A growing body of research has employed both CTT and IRT to assess the internal consistency of measures, particularly for cognitive abilities or related constructs. These studies have contributed to our understanding of the advantages and limitations of each approach in evaluating the reliability of cognitive assessments.
Embretson (1996) compared the use of CTT and IRT in evaluating the internal consistency of a measure of verbal ability, the Wechsler Adult Intelligence Scale-Revised (WAIS-R) Vocabulary subtest. The study found that the IRT approach provided more detailed information about item and test functioning, such as item discrimination and item difficulty parameters. Furthermore, the IRT analysis revealed that the test provided more accurate and reliable estimates for individuals with average to high verbal ability levels, while the CTT-based reliability estimates remained constant across all ability levels.
Reise and Waller (2009) used both CTT and IRT to assess the internal consistency of a measure of reading comprehension, the Nelson-Denny Reading Test (NDRT). Their study revealed that IRT-based reliability estimates varied across ability levels, with higher reliability for individuals with average to high reading comprehension abilities. In contrast, the CTT-based estimates remained constant, providing a less nuanced understanding of the test's reliability across different ability levels. The study also highlighted the usefulness of IRT for detecting items that function differently for various subgroups of examinees.
Van Der Linden and Glas (2010) examined the reliability of a cognitive abilities test battery using both CTT and IRT methods. Their research demonstrated that IRT-based reliability estimates were generally higher than those obtained using CTT methods. The IRT approach also allowed for the evaluation of the test's reliability at different ability levels, providing a more comprehensive understanding of the test's functioning.
Issues Related to the Use of CTT and IRT for Assessing Internal Consistency.
The assumption of unidimensionality is a key issue in both CTT and IRT. Unidimensionality implies that a test measures a single underlying construct, and all the items in the test load onto that one construct. Violations of unidimensionality can lead to inflated internal consistency estimates, as the test may appear to be more reliable than it truly is. Consequently, it is essential to confirm the unidimensionality of a test before applying either CTT or IRT methods (Reise, 2012).
Methods for evaluating unidimensionality include exploratory factor analysis (EFA), confirmatory factor analysis (CFA), and multidimensional scaling (MDS; McDonald, 1999). These approaches help researchers determine whether a test's items load onto a single factor or multiple factors, which can inform the appropriate use of CTT or IRT.
Test length is another issue related to the use of CTT and IRT for assessing internal consistency. Longer tests generally have higher internal consistency estimates, as the increased number of items allows for more stable estimates of the underlying construct (Sijtsma, 2009). This relationship between test length and internal consistency can lead to biased comparisons between tests of different lengths, as longer tests may appear to be more reliable than shorter tests simply because of their length (Nunnally, 1978).
To overcome this issue, researchers can use the Spearman-Brown prophecy formula, which adjusts the reliability estimate for tests of different lengths (Brown, 1910; Spearman, 1910). Additionally, the use of IRT-based methods, such as test information functions (TIFs), can help to overcome issues related to test length, as these methods provide a more detailed account of the reliability across different levels of ability (Lord, 1980).
Local independence is another critical assumption for both CTT and IRT models (Lord & Novick, 1968). Local independence implies that the responses to the items in a test are independent of each other after controlling for the underlying ability. Violations of local independence, such as when items are dependent on one another (e.g., due to item redundancy), can result in inflated reliability estimates (Yen, 1984).
To assess local independence, researchers can use techniques such as residual correlation analysis and Q3 statistics (Chen & Thissen, 1997). When violations of local independence are detected, modifications to the test or the use of multidimensional IRT models may be necessary to account for the dependencies between items (Adams, et al., 1997)
Finally, the issue of model fit is relevant for both CTT and IRT approaches. It is essential to select the appropriate model for the data to obtain accurate reliability estimates (Baker, 2001). Poor model fit can lead to biased estimates of internal consistency and other psychometric properties.
Various methods can be used to assess model fit, including likelihood ratio tests, information criteria (e.g., Akaike Information Criterion and Bayesian Information Criterion), and graphical techniques such as item characteristic curves (ICCs) and item response functions (IRFs; Embretson & Reise, 2000). Choosing the right model is crucial to ensure the accurate assessment of a test's internal consistency and other psychometric properties.
Method
Participants
The present study involved a total of 1,079 participants, comprising 70.16% males and 29.84% females. The age of the participants ranged from 8 to 72 years, with a mean age of 30.14 years and a standard deviation of 11.97 years. No inclusion and exclusion criteria was set. The study aimed to explore the psychometric properties of the Jouve Cerebrals Crystallized Educational Scale (JCCES) in a large and unselected sample, hoping for the generalization of the results and enhance the validity and reliability of the assessment tool.
Materials
The Jouve Cerebrals Crystallized Educational Scale (JCCES) was the only instrument utilized in the study. The JCCES is a computerized, self-administered, and untimed assessment designed to measure crystallized cognitive abilities, focusing on verbal analogies (VA), mathematical problems (MP), and general knowledge (GK) questions. The scale consists of 41 VA items, 32 MP items, and 56 GK items, totaling 129 items. The VA and GK items together comprise the JCCES verbal scale.
The JCCES was administered using an online platform, and participants completed the test individually at their own pace. The test was designed so that items were not presented in acsending order of difficulty, with some very easy among very difficult ones in order to ensure a reliable data analysis by assessing the quality of test-taking. Modifications to the original version of the JCCES were minimal and primarily involved updating the instructions and formatting to facilitate a smooth and efficient administration.
Procedures
The study followed a cross-sectional design to collect data on participants' performance on the JCCES. Participants were also informed that their data would be kept confidential and used only for research purposes. The researchers also ensured that the study adhered to the ethical guidelines set forth by the American Psychological Association (APA, 2017).
Instructions for completing the assessment were provided on-screen, prior to the test questionnaire. The test was untimed, allowing participants to work at their own pace. The order in which the test items were presented did not correspond to their level of difficulty, and the difficulty level of the items was not adapted based on the participant's performance. This format aimed to display all the items to each participant, ensuring an accurate data collection for all the items of the JCCES.
Upon completion of the JCCES, participants' responses were collected and stored in a secure database for subsequent analysis. Data quality checks were conducted to ensure the reliability and validity of the data, such as screening for missing data, outliers, and other anomalies.
Data Analysis
The data were analyzed using both Classical Test Theory (CTT) and Item Response Theory (IRT) methods (Hambleton & Swaminathan, 1985; Lord, 1980). The primary focus of the analysis was on the reliability and internal consistency of the JCCES, as well as the identification of the most relevant solutions to be included as answer keys. Kernel estimator and Bayes modal estimator methods were employed to analyze participants' responses on the JCCES.
Descriptive statistics were calculated for each item, including difficulty level, standard deviation, and polyserial correlation values (Drasgow, 1986). The internal consistency of the entire test and the subtests was assessed using Cronbach's alpha (Cronbach, 1951). A two-parameter logistic model (2PLM) with a fixed slope and varying difficulty parameters was applied to the data, allowing for a more comprehensive evaluation of the items' psychometric properties. The fit of the 2PLM to the data was then assessed.
Results
Statistical Analyses
The research hypotheses were tested using Classical Test Theory (CTT; Novick, 1966) and Item Response Theory (IRT; van der Linden & Hambleton, 1997) methods, such as kernel estimator and Bayes modal estimator. These methods were employed to analyze the answers provided by 1,079 examinees on the Jouve Cerebrals Crystallized Educational Scale (JCCES). The primary focus was on reliability and internal consistency, which led to the inclusion of the most relevant solutions as answer keys. The two-parameter logistic model (2PLM) with a normal ogive was used as the model for the Bayes modal estimator (BME) method.
Classical Test Theory (CTT)
The internal consistency of the entire test was assessed, a critical aspect of test reliability. The analysis revealed a Cronbach's Alpha of .96 for the scores on the JCCES, indicating excellent internal consistency. This value is highly comparable to standardized cognitive ability batteries such as the Wechsler's (1997, 2008). Furthermore, the subtest scores demonstrated strong reliability, with alpha coefficients of .81 for verbal analogies (VA), .91 for mathematical problems (MP), and .93 for general knowledge (GK) questions. A notably high Cronbach's Alpha of .94 was also observed for the JCCES verbal scale scores, which comprised the VA subtest and the GK questions. The measurement error for the JCCES total score is within an acceptable range (SEm = 3.92).
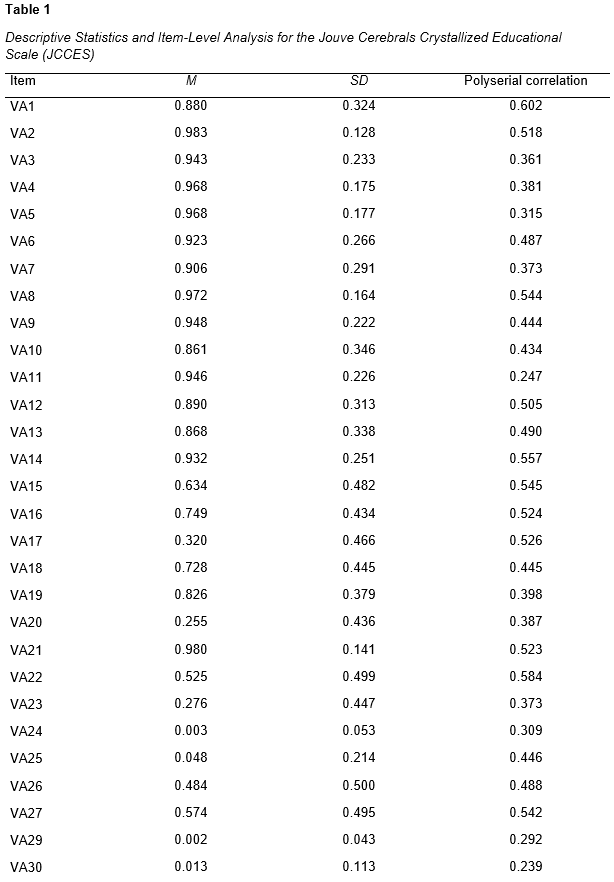
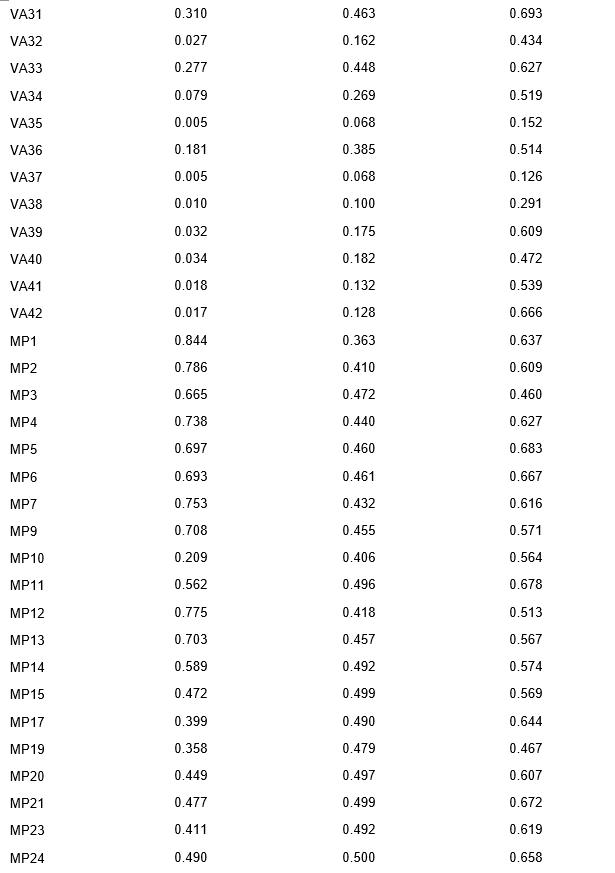
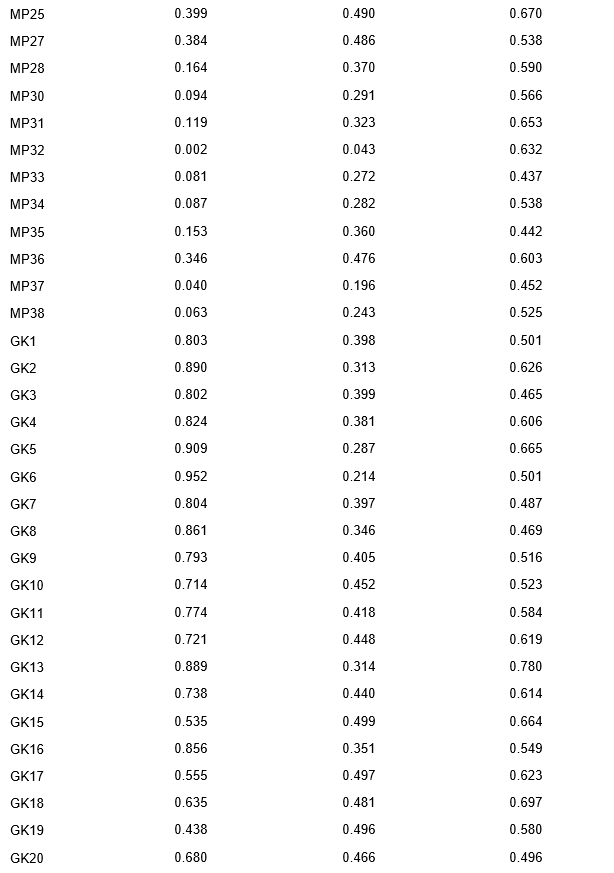
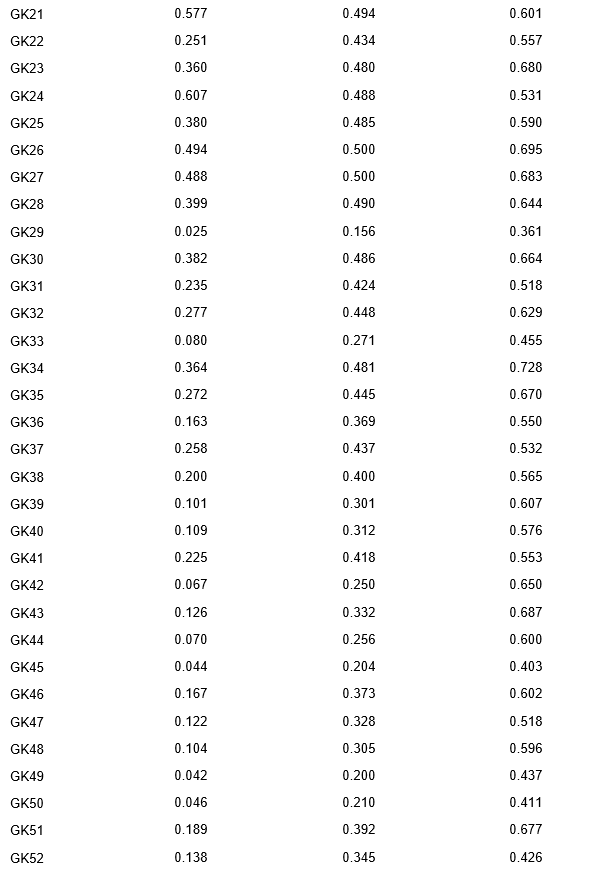
Table 1 presents the descriptive statistics and item-level analysis of the JCCES items, showing the levels of difficulty, standard deviation, and polyserial correlation. The results reveal that the JCCES items cover a wide range of cognitive ability levels and content areas.
For the VA items, the mean difficulty ranges from 0.003 (VA24) to 0.983 (VA2), with a standard deviation that spans from 0.053 (VA24) to 0.324 (VA1). Polyserial correlation values range from 0.247 (VA11) to 0.693 (VA31).
The MP items have varying levels of difficulty, standard deviation, and polyserial correlation. The mean difficulty ranges from 0.002 (MP32) to 0.844 (MP1), with a standard deviation that ranges from 0.043 (MP32) to 0.496 (MP11). Polyserial correlation values range from 0.437 (MP33) to 0.683 (MP5).
Similarly, the GK items show a wide range of difficulty levels, with mean difficulty values ranging from 0.025 (GK29) to 0.890 (GK2). The standard deviation values range from 0.156 (GK29) to 0.499 (GK15). Polyserial correlation values range from 0.361 (GK29) to 0.780 (GK13).
These results suggest that the JCCES items present a heterogeneous set of difficulty levels, standard deviations, and polyserial correlation values. This diversity allows for a comprehensive evaluation of individuals' cognitive skills.
     |
|---|
Item Response Theory (IRT)
Kernel Estimator: Option Characteristic Curves (OCC).
In this comprehensive study, an in-depth analysis of the answers provided by 1,079 examinees was conducted using kernel estimation to identify the most relevant solutions and incorporate them as answer keys for the JCCES. The kernel estimator is particularly effective in the context of problems such as verbal analogies, where the primary focus is on reasoning abilities rather than vocabulary and lexical knowledge. As a result, it is more appropriate to prioritize different reasoning axes and not restrict success to a single lexical orientation.
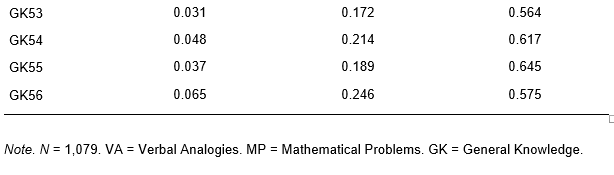
To exemplify the methodology employed in analyzing the responses to the items of the JCCES, we have selected two examples that highlight the distinct response patterns observed among examinees.
The first example illustrates an item with only one correct answer. As depicted in Figure 1, three answers clearly emerge from the examinees' responses, namely OCC #1, OCC #2, and OCC #3. The first option characteristic curve (OCC) is shown in a continuous line and black color, representing the unique correct answer. This OCC ranges from -4 to 6 and follows a sigmoid pattern. Adjacent to this OCC, the item characteristic curve (ICC) for the two-parameter logistic model (2PLM) is displayed in a dotted line, illustrating the item when scored dichotomously. The other two OCCs of interest are #3, which represents the lack of response and is characterized by a curve that decreases as ability increases, and OCC #2, reflecting an answer provided by examinees of low ability. In this item, there is little room for debate, as there is only one solution that is evidently correct.
 |
|---|
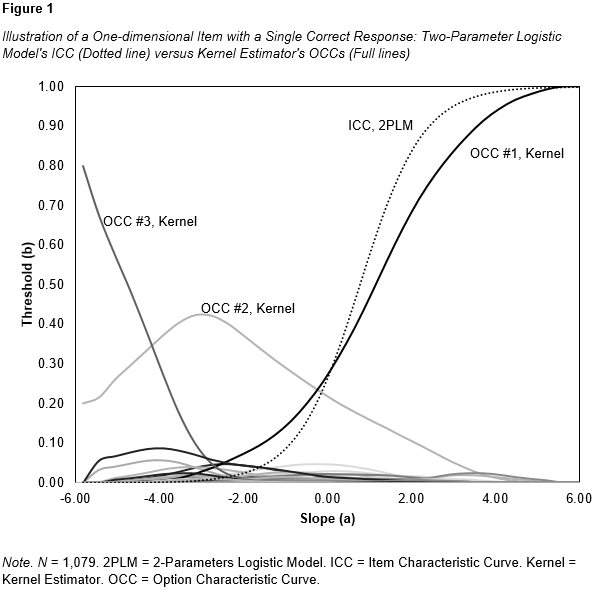
In contrast, as displayed in Figure 2, the second example demonstrates a more complex response pattern. Although OCC #1 is the most frequent correct answer, OCC #2 serves as a viable alternative used by approximately 20 to 30% of test-takers across almost the entire ability spectrum. When both responses are considered valid and awarded one point, the discrimination parameter significantly increases. The ICC (dotted line) displays the item's performance when scored dichotomously, taking both valid responses into account.
 |
|---|
This analysis using kernel estimation not only enables a more accurate evaluation of examinees' abilities but also highlights the importance of considering alternative answers in test design. Recognizing various reasoning approaches and understanding the nuances of examinees' responses allow for a more inclusive assessment of cognitive skills, which ultimately results in a more equitable evaluation of the population.
Furthermore, the study's findings can inform future test development and refinement, ensuring that items are better designed to capture the diverse reasoning abilities of examinees. This approach ultimately enhances the validity and reliability of the JCCES as a measure of crystallized cognitive skills. By promoting a better understanding of examinees' response patterns and reasoning strategies, the test can better serve its purpose as a tool for assessing individuals' cognitive abilities and inform educational interventions and research.
Two-Parameters Logistic Model (2PLM): Test of Fit.
In this analysis, the estimation process was conducted using the Baye's modal estimator (BME) method and a two parameters logistic model (2PLM) with a normal ogive. The process successfully converged for all items, and no items were ignored during the estimation.
     |
|---|
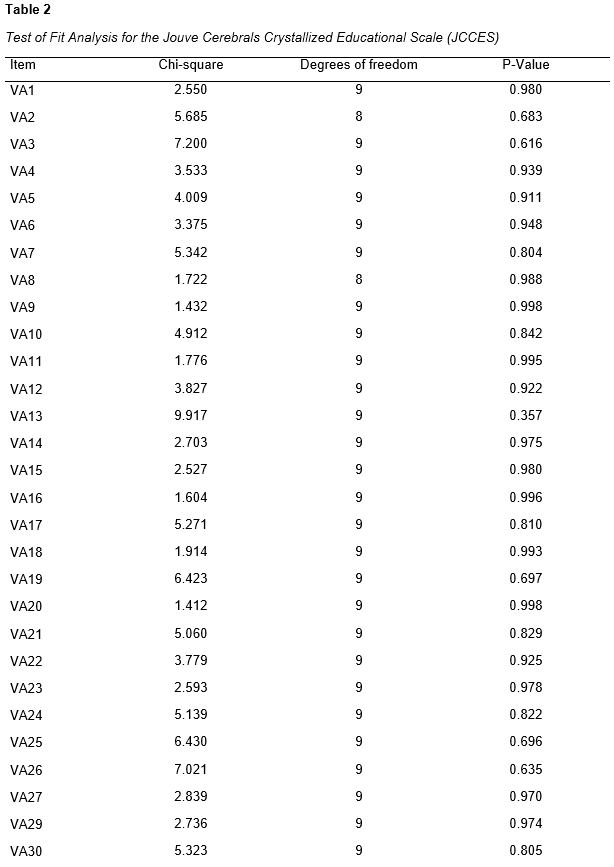
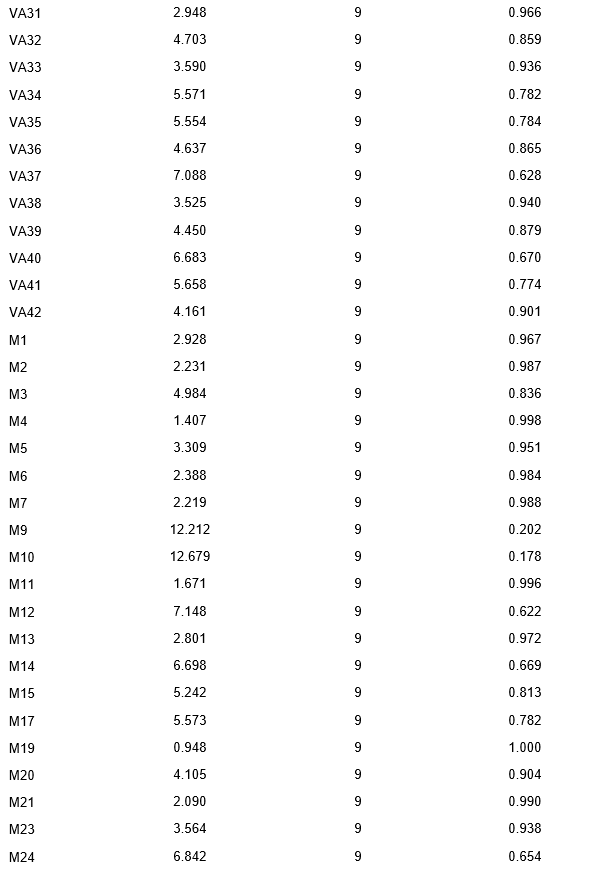
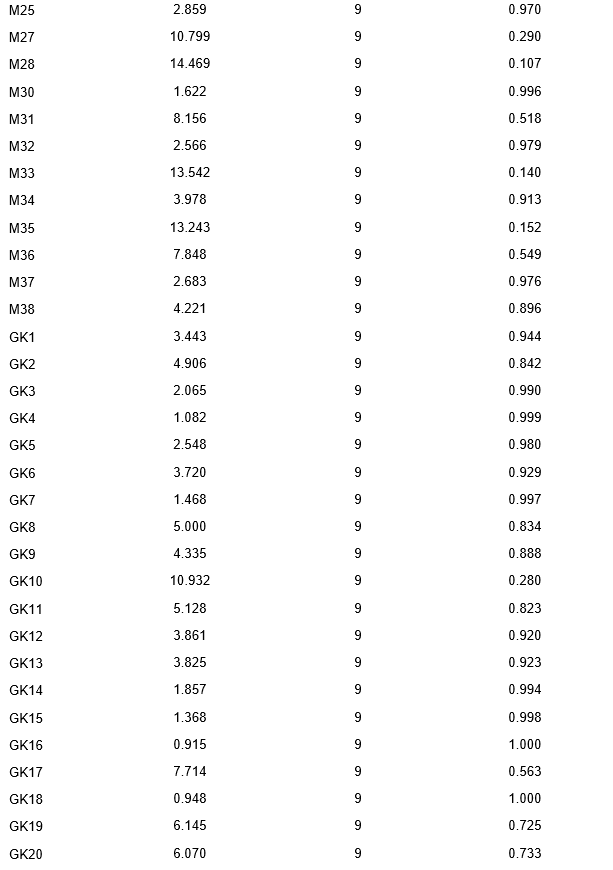
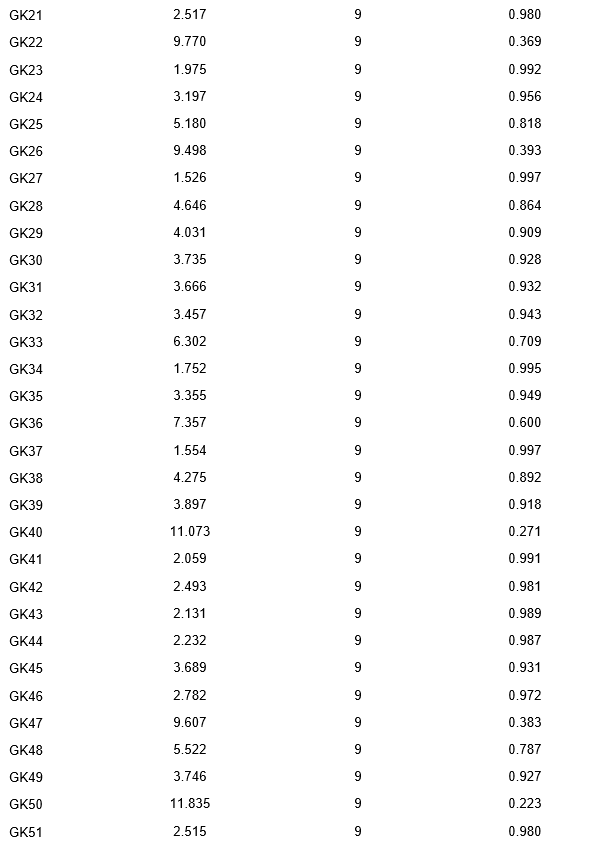
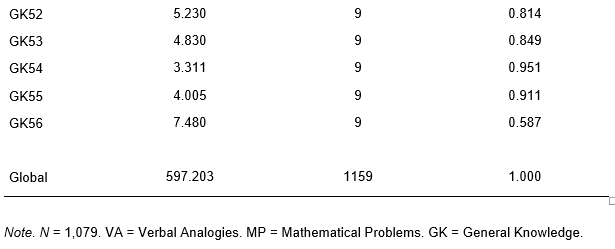
As provided in Table 2, a test of fit was performed on the items, yielding Chi-square, degrees of freedom, and p-value results. For instance, item VA1 had a Chi-square value of 2.550, 9 degrees of freedom, and a p-value of 0.980. Similarly, VA3 presented a Chi-square value of 7.200, 9 degrees of freedom, and a p-value of 0.616. Items VA13 and VA37 had Chi-square values of 9.917 and 7.088, both with 9 degrees of freedom and p-values of 0.357 and 0.628, respectively.
As we move further into the dataset, item MP9 had a Chi-square value of 12.212, 9 degrees of freedom, and a p-value of 0.202. In contrast, item MP38 had a lower Chi-square value of 4.221, 9 degrees of freedom, and a p-value of 0.896.
For the GK series, GK10 had a Chi-square value of 10.932, 9 degrees of freedom, and a p-value of 0.280. In comparison, GK16 had a Chi-square value of 0.915, 9 degrees of freedom, and a p-value of 1.000.
The global fit results indicated a Chi-square value of 597.203, 1159 degrees of freedom, and a p-value of 1.000.
In interpreting these results, it is essential to consider that a higher p-value indicates a better fit of the model to the data. Most items have a p-value close to or equal to 1, suggesting that the model provides a good fit for the majority of the items. However, some items, such as VA13, MP9, and GK50, have lower p-values, which could indicate a poorer fit of the model for these specific items.
Two-Parameters Logistic Model (2PLM): Item Parameters.
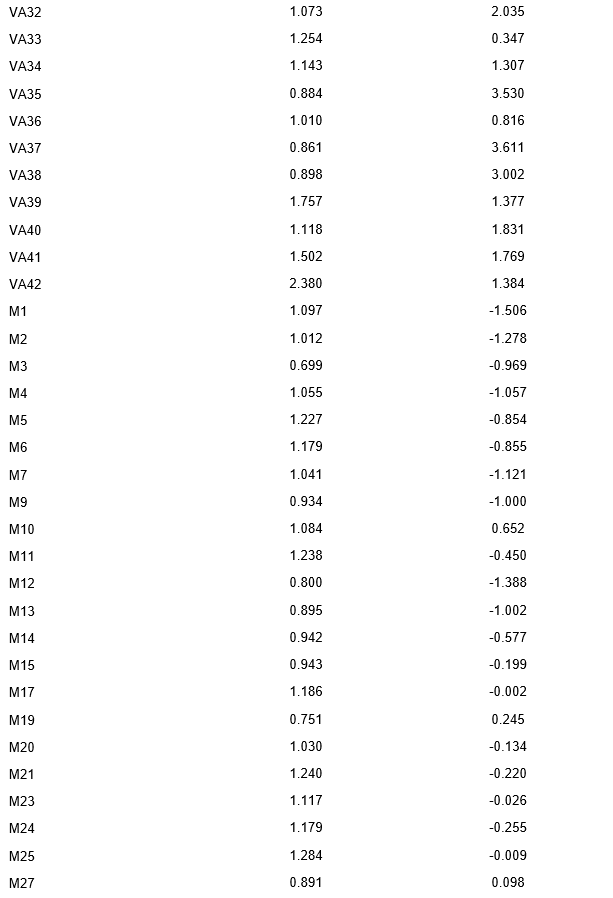
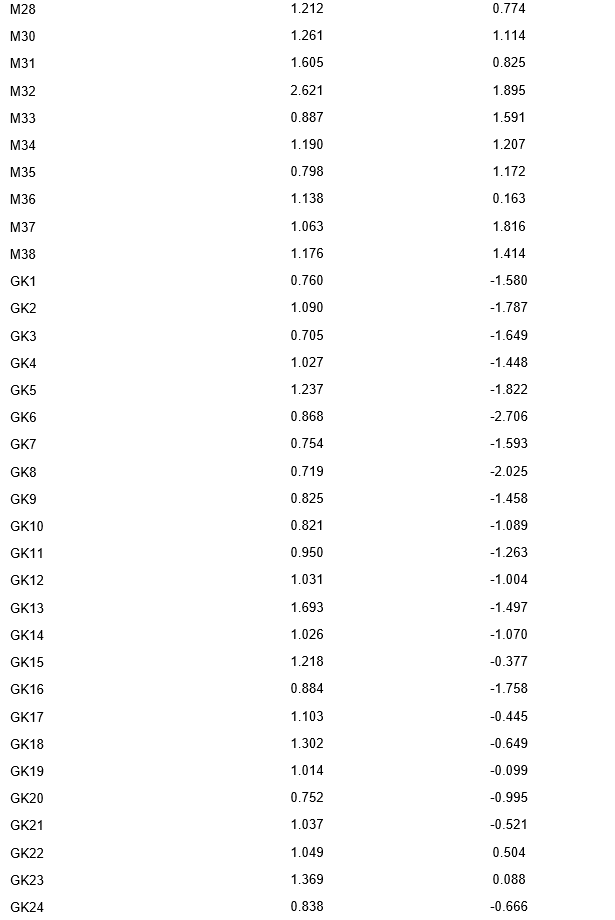
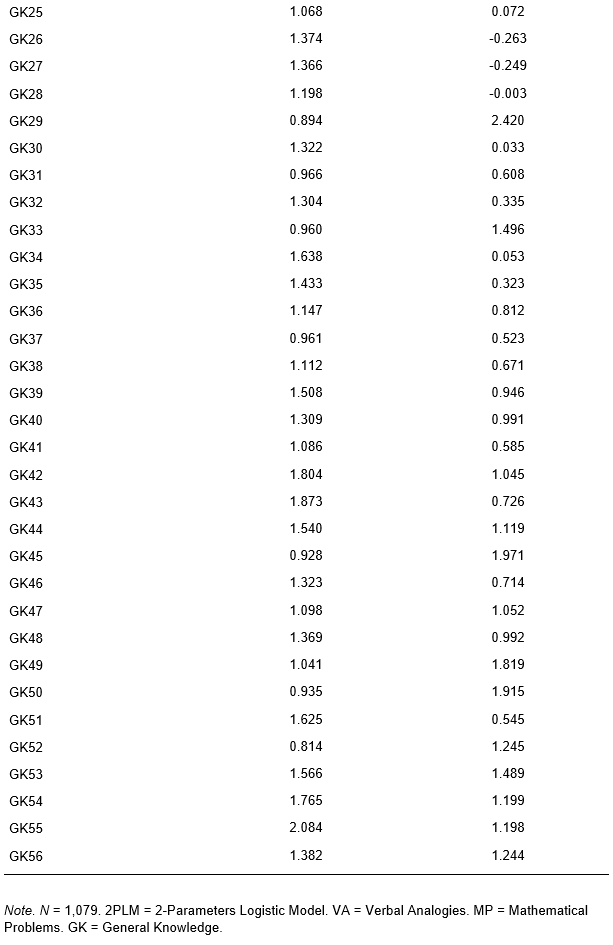
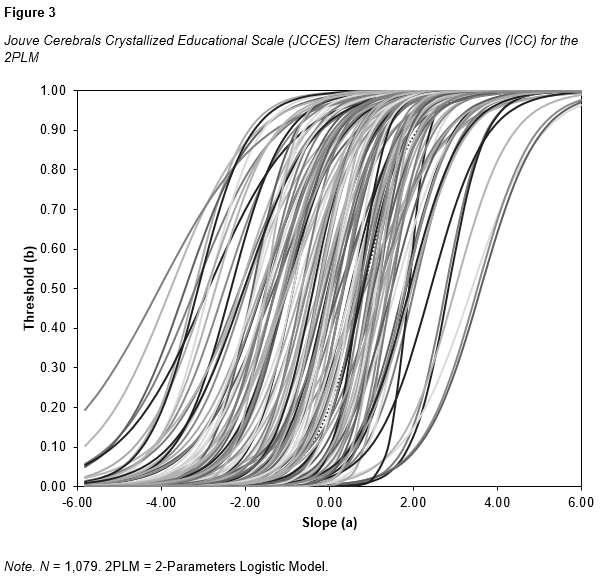
This part of the study aims to present and interpret the parameter estimates for each item in the JCCES, specifically the slope (a) and threshold (b) parameters. Table 3 displays all the parameters and Figure 3 gaphically illustrates Item Characteristic Curves (ICC) drawn with these parameters.
    |
|---|
 |
|---|
For the Verbal Analogies (VA) section, the discrimination ability of items, represented by slope values, ranged from 0.474 (VA11) to 2.380 (VA42). Higher slope values, such as VA42 (a = 2.380), indicate greater discrimination ability, suggesting that these items are more effective at distinguishing between test-takers with different levels of verbal analogy skills. In contrast, items with lower slope values, like VA11 (a = 0.474), have a lower discrimination ability and may be less informative in differentiating test-takers' abilities. The difficulty level of items, represented by threshold values, ranged from -4.049 (VA11) to 3.611 (VA37). The wide range of threshold values highlights the diverse set of difficulties encompassed by the VA items, allowing for the evaluation of test-takers with varying levels of verbal analogy skills.
For the Mathematical Problems (MP) section, the slope values ranged from 0.699 (MP3) to 2.621 (MP32), indicating varying discrimination abilities among the items. High slope values, such as MP32 (a = 2.621), suggest that these items can effectively distinguish between test-takers with different levels of mathematical problem-solving skills. On the other hand, items with lower slope values, like MP3 (a = 0.699), may be less sensitive to differences in test-takers' abilities. The threshold values for the MP items ranged from -1.506 (MP1) to 1.895 (MP32), reflecting a diverse set of item difficulties within the mathematical problems section.
In the General Knowledge (GK) section, the slope values ranged from 0.719 (GK8) to 2.084 (GK55), signifying a wide range of discrimination abilities. Items with high slope values, such as GK55 (a = 2.084), are more effective at distinguishing between test-takers with different levels of general knowledge. In contrast, items with lower slope values, like GK8 (a = 0.719), may be less informative in differentiating test-takers' abilities. The threshold values for the GK items ranged from -2.706 (GK6) to 1.971 (GK45), reflecting a diverse set of item difficulties within the general knowledge section.
Discussion
Interpretation of Results
The present study aimed to assess the reliability and internal consistency of the Jouve Cerebrals Crystallized Educational Scale (JCCES) and evaluate the most relevant solutions using classical test theory and item response theory methods (Hambleton & Swaminathan, 1985; Lord, 1980). The findings revealed excellent internal consistency of the JCCES (Cronbach's Alpha = .96) (Cronbach, 1951), which is comparable to standardized cognitive ability batteries such as Wechsler's (1997, 2008). Subtest scores also demonstrated strong reliability, indicating that the JCCES is a reliable measure of crystallized cognitive abilities.
Statistical analyses of item difficulty levels, standard deviations, and polyserial correlations (Drasgow, 1986) indicated a wide range of values, suggesting that the JCCES covers various cognitive abilities and content areas. This diverse set of items allows for a comprehensive evaluation of individuals' cognitive skills (Kyllonen & Christal, 1990). Furthermore, the kernel estimator (Silverman, 1986) identified multiple relevant solutions, emphasizing the importance of considering alternative answers and reasoning approaches in test design.
Implications for Theory, Practice, and Future Research
The findings of this study have several implications for theory, practice, and future research. The JCCES's strong reliability and internal consistency suggest that it is a valid measure of crystallized cognitive abilities. This, in turn, implies that the JCCES can be used effectively in various contexts, such as educational settings (Gardner, 1983), to assess individuals' cognitive skills and inform interventions and research (Sternberg, 1997). Additionally, the diverse set of items supports a comprehensive evaluation of examinees' abilities, promoting equity in assessment (Pellegrino et al., 2001) and helping to identify areas of strength and weakness (Flanagan & McGrew, 1998).
Considering alternative answers and reasoning approaches, as demonstrated by the kernel estimation analysis, highlights the importance of inclusivity in test design (Messick, 1989). Recognizing multiple valid responses enables a more accurate evaluation of examinees' abilities (Kane, 1992) and reduces potential biases. This approach could be applied to other assessments, enhancing their validity and reliability (Baker, 2001).
Future research could explore the JCCES's predictive validity (Cronbach & Meehl, 1955), examining the relationship between JCCES scores and other measures of cognitive ability or educational outcomes (Horn & Cattell, 1966). Moreover, additional studies could investigate potential cultural or linguistic biases in the test items (van de Vijver & Tanzer, 2004) and explore methods to reduce such biases (Hambleton, 2005).
Limitations
While the present study offers valuable insights into the reliability and internal consistency of the JCCES, some limitations must be acknowledged. The sample consisted of 1,079 examinees, which, although sufficient for the analyses conducted (Kline, 2005), may not be fully representative of the broader population. Additionally, the study focused primarily on reliability and internal consistency, without considering other aspects of validity, such as predictive or concurrent validity (Campbell & Fiske, 1959).
Another potential limitation is the use of classical test theory and item response theory methods (Hambleton & Swaminathan, 1985; Lord, 1980), which may not capture all aspects of examinees' cognitive abilities. Alternative methods, such as cognitive diagnostic modeling (Rupp et al., 2010), could provide additional insights into the structure and nature of examinees' skills. Furthermore, although the study identified multiple relevant solutions, it is possible that alternative answers were not considered or that biases in the kernel estimation process (Silverman, 1986) influenced the results.
Future Research Directions
Based on the findings and limitations of this study, several avenues for future research can be identified. First, the study's sample was limited to a specific population, and it would be worthwhile to replicate the research using diverse samples to further investigate the generalizability of the findings (Cook & Campbell, 1979). Additionally, the examination of other cognitive ability tests and comparisons of their psychometric properties would provide valuable insights into the strengths and weaknesses of various assessment tools, ultimately contributing to the development of more effective measures of cognitive abilities (Baker, 2001).
Another direction for future research could involve exploring the impact of various instructional methods or educational interventions on the development of crystallized cognitive abilities, as measured by the JCCES. This could provide valuable information on the effectiveness of different pedagogical approaches (Slavin, 1996) and inform the design of educational programs aimed at enhancing cognitive skills in students (Mayer, 2002).
Furthermore, longitudinal studies could be conducted to track the development of crystallized cognitive abilities over time (McArdle et al., 2002) and investigate factors that contribute to individual differences in cognitive growth (Salthouse, 2004). This would not only inform educational practice but also enhance our understanding of the cognitive processes underlying crystallized intelligence (Cattell, 1971).
In light of the examination with the Kernel Estimator of possible multiple valid answers in many items of the JCCES (especially the Verbal Analogies), future research directions could lead to the exploration of an alternative scoring method. A shift from a dichotomous to a polytomous scoring method may provide a more accurate representation of examinees' cognitive abilities and better acknowledge the existence of multiple valid solutions. This could also enhance the test's sensitivity and specificity, ultimately contributing to its overall psychometric properties (Embretson & Reise, 2000).
This study has provided valuable insights into the psychometric properties of the JCCES and its potential as a tool for assessing crystallized cognitive abilities. The diverse range of items and the inclusion of alternative solutions as answer keys contribute to a comprehensive and inclusive evaluation of examinees' cognitive skills. The findings also highlight the importance of considering different reasoning approaches and understanding the nuances of examinees' responses in the design of cognitive ability tests. By focusing on these aspects, researchers and practitioners can work together to develop more valid and reliable measures of cognitive abilities and contribute to a better understanding of human cognition and its development (Neisser et al., 1996).
Conclusion
The present study examined the reliability of the Jouve Cerebrals Crystallized Educational Scale (JCCES), focusing on its internal consistency and item properties. Results revealed excellent internal consistency (Cronbach's Alpha = .96), suggesting that the JCCES is a reliable instrument for assessing crystallized cognitive abilities. The diverse range of item difficulty, standard deviations, and polyserial correlation values indicate that the JCCES effectively covers various cognitive abilities and content areas, contributing to a comprehensive evaluation of individuals' cognitive skills.
The implications of the findings extend to both theory and practice, as they highlight the importance of considering alternative answers in test design and the need for a more inclusive assessment of cognitive skills. This information can inform future test development and refinement, ultimately enhancing the validity and reliability of the JCCES and similar measures.
Some limitations of the study include the potential for a poorer fit of the model for specific items and the possibility of unexplored alternative answers for certain questions. Future research could address these limitations by refining the model and investigating other response patterns, as well as exploring the application of these findings to other cognitive assessment tools. This could lead to the improvement and extension of the JCCES and contribute to a more robust understanding of the diverse reasoning abilities of individuals, informing educational interventions and research in the field.
In conclusion, the study demonstrates the reliability of the JCCES and highlights the importance of considering various reasoning approaches for a more inclusive and equitable evaluation of cognitive abilities. The findings provide valuable insights for test development and pave the way for future research that further advances our understanding of cognitive assessment.
References
Adams, R. J., Wilson, M. R., & Wu, M. L. (1997). Multilevel item response models: An approach to errors in variables regression. Journal of Educational and Behavioural Statistics, 22(1), 46–75. https://doi.org/10.2307/1165238
Allen, M. J., & Yen, W. M. (2002). Introduction to Measurement Theory. Prospect Heights, IL: Waveland Press.
American Psychological Association. (2017). Publication manual of the American Psychological Association (6th ed.). Washington, DC: Author.
Anastasi, A., & Urbina, S. (1997). Psychological testing (7th ed.). Upper Saddle River, NJ: Prentice Hall.
Baker, F. B. (2001). The basics of item response theory. College Park, MD: ERIC Clearinghouse on Assessment and Evaluation.
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee's ability. In F. M. Lord & M. R. Novick (Eds.), Statistical theories of mental test scores (pp. 397-479). Reading, MA: Addison-Wesley.
Birenbaum, M., & Tatsuoka, K. K. (1987). Open-ended versus multiple-choice response formats—It does make a difference for diagnostic purposes. Applied Psychological Measurement, 11(4), 385-395. https://doi.org/10.1177/014662168701100404
Bock, R. D., & Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters. Psychometrika, 47, 369.
Brown, W. (1910). Some Experimental Results in the Correlation of Mental Abilities. British Journal of Psychology, 3, 296-322. https://doi.org/10.1111/j.2044-8295.1910.tb00207.x
Campbell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56(2), 81-105. https://doi.org/10.1037/h0046016
Carroll, J. B. (1993). Human cognitive abilities: A survey of factor-analytic studies. New York: Cambridge University Press. https://doi.org/10.1017/CBO9780511571312
Cattell, R. B. (1971). Abilities: Their structure, growth, and action. Boston, MA: Houghton Mifflin.
Chen, W.-H., & Thissen, D. (1997). Local dependence indexes for item pairs using item response theory. Journal of Educational and Behavioral Statistics, 22(3), 265-289. https://doi.org/10.2307/1165285
Choi, S. W. (2009). Firestar: Computerized adaptive testing simulation program for polytomous item response theory models. Applied Psychological Measurement, 33(8), 644–645. https://doi.org/10.1177/0146621608329892
Clark, L. A., & Watson, D. (1995). Constructing validity: Basic issues in objective scale development. Psychological Assessment, 7(3), 309-319. https://doi.org/10.1037/1040-3590.7.3.309
Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues for field settings. Boston, MA: Houghton Mifflin.
Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16(3), 297-334. https://doi.org/10.1007/BF02310555
Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281-302. https://doi.org/10.1037/h0040957
Deary, I. J., Strand, S., Smith, P., & Fernandes, C. (2007). Intelligence and educational achievement. Intelligence, 35(1), 13-21. https://doi.org/10.1016/j.intell.2006.02.001
De Ayala, R. J. (2009). The Theory and Practice of Item Response Theory. New York, NY: The Guilford Press. http://dx.doi.org/10.1007/s11336-010-9179-z
Drasgow, F. (1986). Polychoric and polyserial correlations. In L. E. Aiken (Ed.), Encyclopedia of statistical sciences (Vol. 7, pp. 68-74). New York: John Wiley & Sons. http://dx.doi.org/10.1002/0471667196.ess2014
Eisinga, R., Te Grotenhuis, M., & Pelzer, B. (2013). The reliability of a two-item scale: Pearson, Cronbach, or Spearman-Brown? International Journal of Public Health, 58(4), 637-642. https://doi.org/10.1007/s00038-012-0416-3
Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Mahwah, NJ: Lawrence Erlbaum Associates. https://doi.org/10.4324/9781410605269
Fan, X. (1998). Item response theory and classical test theory: An empirical comparison of their item/person statistics. Educational and Psychological Measurement, 58(3), 357–381. https://doi.org/10.1177/0013164498058003001
Flanagan, D. P., & McGrew, K. S. (1998). Interpreting intelligence tests from contemporary Gf-Gc theory: Joint confirmatory factor analysis of the WJ-R and KAIT in a non-white sample. Journal of School Psychology, 36(2), 151-182. https://doi.org/10.1016/S0022-4405(98)00003-X
Gardner, H. (1983). Frames of mind: The theory of multiple intelligences. New York: Basic Books. https://doi.org/10.1177/001698628502900212
Gustafsson, J. E. (1984). A unifying model for the structure of intellectual abilities. Intelligence, 8(3), 179-203. https://doi.org/10.1016/0160-2896(84)90008-4
Hambleton, R. K. (2005). Issues, designs, and technical guidelines for adapting tests into multiple languages and cultures. In R. K. Hambleton, P. F. Merenda, & C. D. Spielberger (Eds.), Adapting educational and psychological tests for cross-cultural assessment (pp. 3-38). Mahwah, NJ: Lawrence Erlbaum. https://doi.org/10.4324/9781410611758
Hambleton, R. K., & Jones, R. W. (1993). Comparison of classical test theory and item response theory and their applications to test development. Educational Measurement: Issues and Practice, 12(3), 38-47. https://doi.org/10.1111/j.1745-3992.1993.tb00543.x
Hambleton, R. K., & Swaminathan, H. (1985). Item response theory: Principles and applications. Boston, MA: Kluwer Academic Publishers.
Horn, J. L., & Cattell, R. B. (1966). Refinement and test of the theory of fluid and crystallized general intelligences. Journal of Educational Psychology, 57(5), 253-270. https://doi.org/10.1037/h0023816
Jouve, X. (2023). Jouve Cerebrals Crystallized Educational Scale. Retrieved from https://www.cogn-iq.org/jouve-cerebrals-educational-scale.php.
Kane, M. T. (1992). An argument-based approach to validity. Psychological Bulletin, 112(3), 527-535.
Kline, R. B. (2005). Principles and practice of structural equation modeling. New York: Guilford Press. https://doi.org/10.1177/1049731509336986
Kyllonen, P. C., & Christal, R. E. (1990). Reasoning ability is (little more than) working-memory capacity?! Intelligence, 14(4), 389-433. https://doi.org/10.1016/S0160-2896(05)80012-1
Lord, F. M. (1980). Applications of item response theory to practical testing problems. Mahwah, NJ: Lawrence Erlbaum. https://doi.org/10.4324/9780203056615
Lord, F. M., & Novick, M. R. (1968). Statistical theories of mental test scores. Menlo Park, CA: Addison-Wesley.
Mayer, R. E. (2002). Rote versus meaningful learning. Theory Into Practice, 41(4), 226-232. https://doi.org/10.1207/s15430421tip4104_4
McArdle, J. J., Ferrer-Caja, E., Hamagami, F., & Woodcock, R. W. (2002). Comparative longitudinal structural analyses of the growth and decline of multiple intellectual abilities over the life span. Developmental Psychology, 38(1), 115-142. https://doi.org/10.1037/0012-1649.38.1.115
McDonald, R. P. (1999). Test theory: A unified treatment. New York: Lawrence Erlbaum.
Messick, S. (1989). Validity. In R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 13-103). New York: American Council on education and Macmillan.
Neisser, U., Boodoo, G., Bouchard, T. J., Jr., Boykin, A. W., Brody, N., Ceci, S. J., Halpern, D. F., Loehlin, J. C., Perloff, R., Sternberg, R. J., & Urbina, S. (1996). Intelligence: Knowns and unknowns. American Psychologist, 51(2), 77–101. https://doi.org/10.1037/0003-066X.51.2.77
Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric theory (3rd ed.). New York: McGraw-Hill. https://doi.org/10.1177/014662169501900308
Novick, M. R. (1966). The axioms and principal results of classical test theory. Journal of Mathematical Psychology, 3(1), 1-18. https://doi.org/10.1016/0022-2496(66)90002-2
Pellegrino, J. W., Chudowsky, N., & Glaser, R. (2001). Knowing what students know: The science and design of educational assessment. Washington, DC: National Academies Press.
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Danish Institute for Educational Research.
Reckase, M. D. (2009). Multidimensional item response theory. New York: Springer. https://doi.org/10.1007/978-0-387-89976-3
Reise, S. P. (2012). The rediscovery of bifactor measurement models. Multivariate Behavioral Research, 47(5), 667–696. https://doi.org/10.1080/00273171.2012.715555
Reise, S. P., & Waller, N. G. (2009). Item response theory and clinical measurement. Annual Review of Clinical Psychology, 5, 27-48. https://doi.org/10.1146/annurev.clinpsy.032408.153553
Rupp, A. A., Templin, J., & Henson, R. A. (2010). Diagnostic measurement: Theory, methods, and applications. New York: Guilford Press.
Salthouse, T. A. (2004). What and when of cognitive aging. Current Directions in Psychological Science, 13(4), 140-144. https://doi.org/10.1111/j.0963-7214.2004.00293.x
Silverman, B. W. (1986). Density estimation for statistics and data analysis. London, UK: Chapman and Hall. http://dx.doi.org/10.1007/978-1-4899-3324-9
Sirin, S. R. (2005). Socioeconomic status and academic achievement: A meta-analytic review of research. Review of educational research, 75(3), 417-453. https://doi.org/10.3102/00346543075003417
Sijtsma, K. (2009). On the use, the misuse, and the very limited usefulness of Cronbach’s alpha. Psychometrika, 74(1), 107–120. https://doi.org/10.1007/s11336-008-9101-0
Slavin, R. E. (1996). Research on cooperative learning and achievement: What we know, what we need to know. Contemporary Educational Psychology, 21(1), 43-69. https://doi.org/10.1006/ceps.1996.0004
Spearman, C. (1904). "General intelligence," objectively determined and measured. The American Journal of Psychology, 15(2), 201-292. https://doi.org/10.2307/1412107
Spearman, C. (1910). Correlation calculated from faulty data. British Journal of Psychology, 3(3), 271-295. https://doi.org/10.1111/j.2044-8295.1910.tb00206.x
Sternberg, R. J. (1997). Successful intelligence. New York: Plume.
Streiner, D. L. (2003). Starting at the beginning: An introduction to coefficient alpha and internal consistency. Journal of Personality Assessment, 80(1), 99-103. https://doi.org/10.1207/S15327752JPA8001_18
Tavakol, M., & Dennick, R. (2011). Making sense of Cronbach's alpha. International Journal of Medical Education, 2, 53-55. http://dx.doi.org/10.5116/ijme.4dfb.8dfd
Thurstone, L. L. (1938). Primary mental abilities. Chicago, Il: University of Chicago Press.
van der Linden, W. J., & Glas, C. A. W. (Eds.). (2010). Elements of adaptive testing. New York: Springer.
van der Linden, W. J., & Hambleton, R. K. (1997). Handbook of modern item response theory. New York: Springer.
van de Vijver, F. J., & Tanzer, N. K. (2004). Bias and equivalence in cross-cultural assessment: An overview. European Review of Applied Psychology, 54(2), 119-135.
Wechsler, D. (1955). Manual for the Wechsler adult intelligence scale. San Antonio, TX: The Psychological Corporation.
Wechsler, D. (1997). Wechsler Adult Intelligence Scale - Third Edition (WAIS-III). San Antonio, TX: The Psychological Corporation.
Wechsler, D. (2008). Wechsler Adult Intelligence Scale-Fourth Edition (WAIS-IV). San Antonio, TX: Pearson.
Woodcock, R. W., & Johnson, M. B. (1989). Woodcock-Johnson Psycho-Educational Battery-Revised. Allen, TX: DLM Teaching Resources.
Yen, W. M. (1984). Effects of local item dependence on the fit and equating performance of the three-parameter logistic model. Applied Psychological Measurement, 8(2), 125-145. https://doi.org/10.1177/014662168400800201
Zimmerman, D. W., & Williams, R. H. (1982). Gain scores in research can be highly reliable. Journal of Educational Measurement, 19(2), 149-154. https://doi.org/10.1111/j.1745-3984.1982.tb00124.x